Data Ingestion Pipeline
This post is part 1 of cloud data architecture series. I will write about the design choices made when designing a sales data ingestion pipeline on Azure.
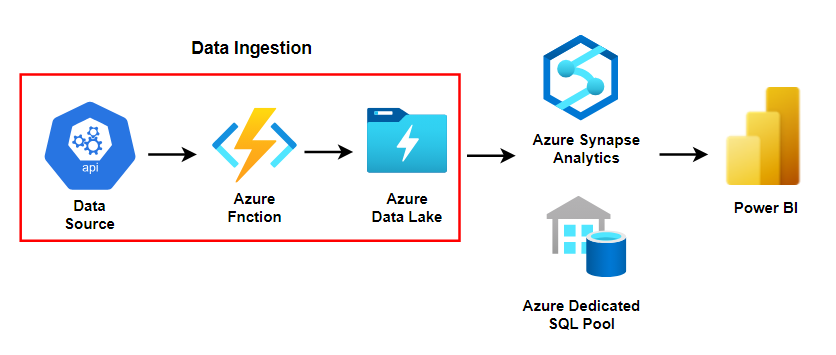
What business use case will this data pipeline used for?
i) Reporting and analytics: Management can monitor the sales trends of each outlets over time, marketing team can evaluate effectiveness of campaign.
ii) Machine learning: Future sales can be forecasted with Machine Learning model, predicting future demand helps outlets to reduce wastages and also manage manpower better.
What are the data sources and data format?
Sales data are kept in POS system in all the outlets. We can extract them by using the POS system API. The data format will be in JSON.
Are we collecting data in batches or streaming?
We ingest data from API by batch because
- lower cost than streaming
- can be scheduled at night, we do not want BI reports to be refreshed during the day when end users are using them.
- there are no business reasons to get real time sales data.
Where do we store collected data?
We store ingested data to data lake because
- data lake do not have strict data schema, if our 3rd party API changes their data schema, it will not break our data pipeline.
- cheaper compared to storing in data warehouse, better to put raw data in data lake to lower storage cost.
In Azure, we choose ADLS Gen 2 (specialized type of blob storage) as our data lake because:
- cheapest storage in Azure.
- has hierarchical namespace, we can have a hierarchical folder structure to organize our data by dates and sources.